Building with AI: Git-based vs headless vs traditional CMS

Monolithic platforms like WordPress and Drupal were built for a world where content strategy meant scheduling blog posts. Then headless came along, solved a few problems, and created a few new ones. Now we’re asking an entirely new question: can your AI agent work with your CMS?
Without simplifying things too much, the answer comes down to where your content lives.
The monolithic CMS has had its day Direct link to this section
WordPress, Drupal and Sitecore had a good run. They also share a structural problem: your content is welded to everything around it. Database, templates, business logic, the content itself: everything is bundled together in a single deployable unit.
The schema itself is the lock-in, in post types, meta tables, taxonomies, and the rendering logic that turns raw rows into something more meaningful. If you extract the data from a WordPress database, you end up with fragments. Making them useful again means rebuilding the platform that understood them, or working with routes through a layer of abstraction to reach content that lives behind a rendering engine.
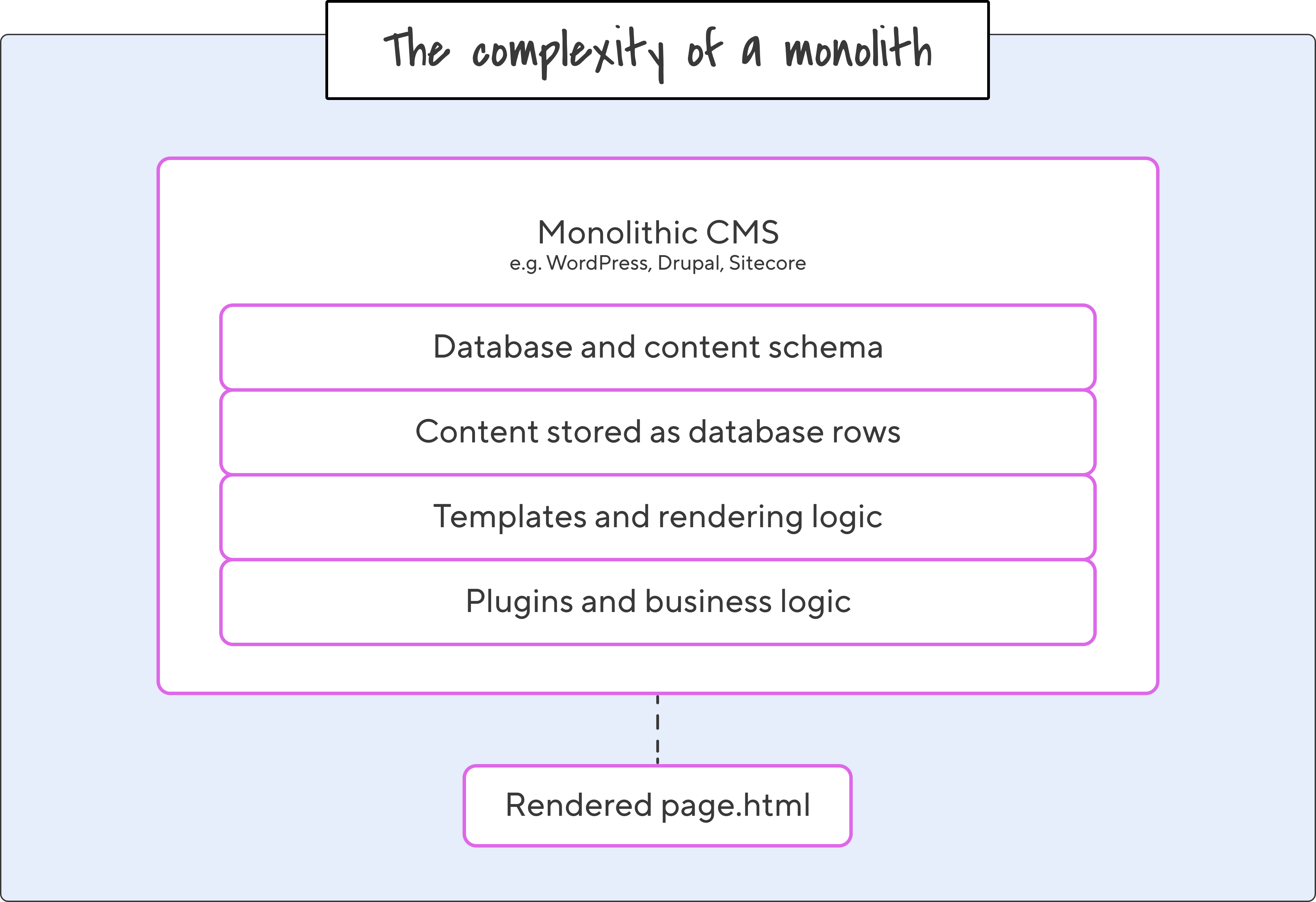
That's a long way from working with content directly, and if you’re an agency trying to move efficiently, you’re still working on a single thread at a time. If only there were some way to … branch out.
Headless solved the wrong problem Direct link to this section
Headless CMSs like Contentful, Sanity, and Storyblok arrived with a pretty compelling pitch. Decouple the frontend from the backend, deliver content via API, and let developers build whatever they want on top.
That’s very useful: frontend flexibility is an advantage. But these headless platforms made a trade-off: they moved your content out of the monolith and straight into another proprietary database. Your content is still locked away, but now it’s behind a different vendor’s API instead.
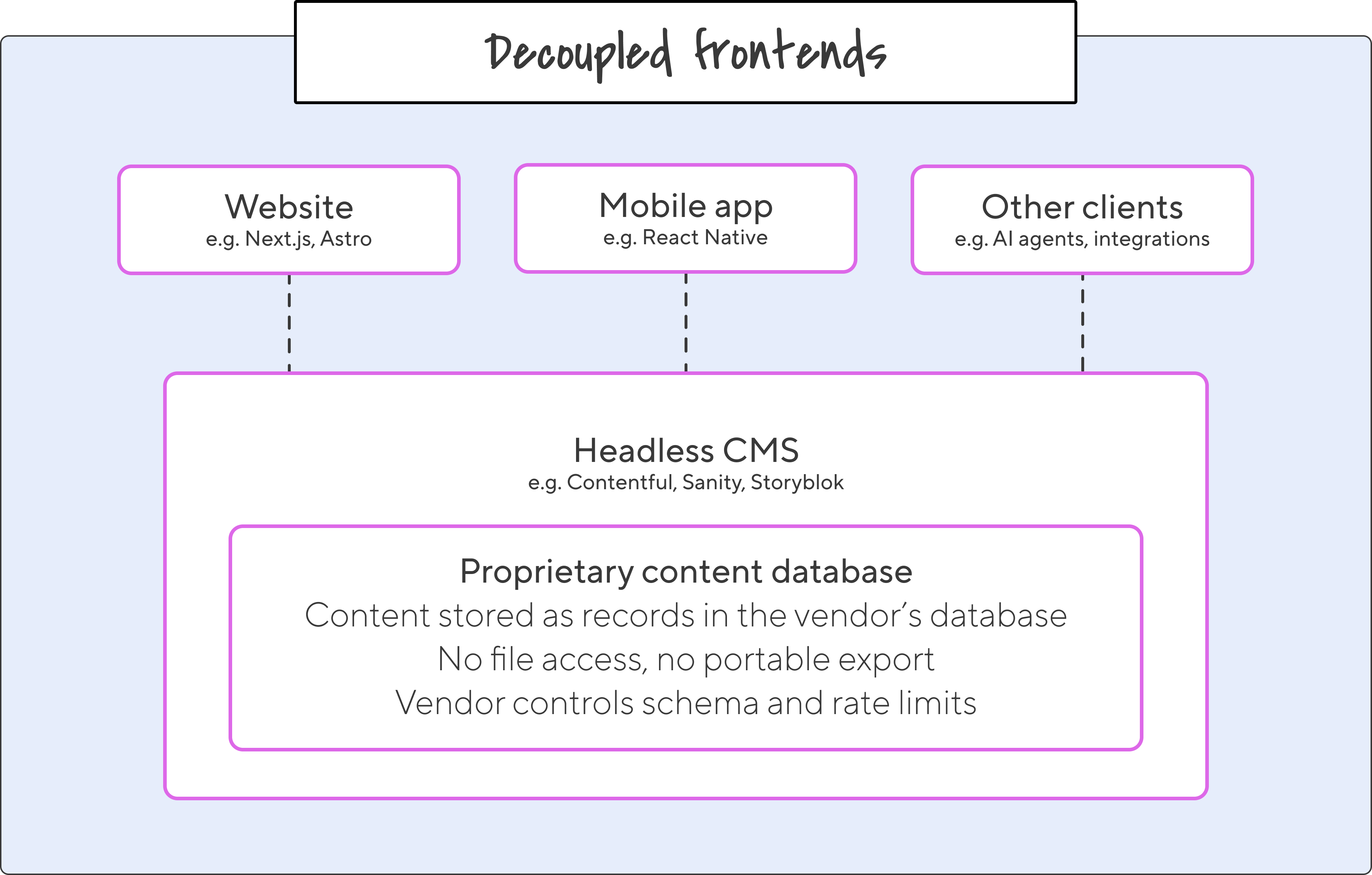
Unfortunately, your content is accessible only through their API, on their terms. These aren’t files you can easily open, read, version, or move.
Even worse, switching providers or backing up your content in a friendlier format isn’t exactly straightforward. And if you want an AI agent to crawl your full content library, you’re building and maintaining API integrations, handling pagination, and managing authentication before it reads a single word. Then there's the latency: a file read that should take milliseconds becomes a network round trip measured in seconds. The larger your content, the more an agent has to fetch and parse, burning tokens on work a local file read would have done for free.
Git-based is a structural advantage Direct link to this section
In my view, Git-based wins outright. With a Git-based CMS like CloudCannon, your content lives in a Git repository as plain files, right next to the code that renders it. You own the files, in formats that have been stable for decades and will keep working long after any platform's API has been deprecated.
The whole system runs on version control. Every edit becomes a Git commit with a real author, timestamp, and diff. You can roll back any change, branch content the way developers branch code, and deploy content and code together so your staging environment actually reflects production. Every change flows through the repository you control. And as AI agents write more of your code, Git is what stops their contributions from turning into a black box.
If your content never lived in Git, your code history only ever told half the story. Check out a commit from last month and you won't get last month's site, because the content that version expected has since changed in a database somewhere else. Change your content model and the old version of your site is effectively gone. Going back is hard. Keeping content outside Git breaks half of what Git is for.
That gap is widest if you switch CMS providers. With headless, you're rebuilding your content model in a new system and migrating everything across, with no reliable past state to fall back on if it goes wrong.
With a Git-based CMS, your content stays put. You're just telling a different tool how to read the files you already have, and you always retain your site's version history. There's still some configuration work (any CMS needs to understand your content shape, after all) but it's a much smaller migration, and one you can actually walk away from.
Changing your content model is one commit Direct link to this section
This is where we talk about velocity — possibly the most important feature of a tool you use every day. In a headless setup, your content model lives in the CMS and your code is built to match it. Change one without the other and things break. So adding multiple authors to a blog post, or dropping a field you no longer need, becomes a careful operation: update the model in staging, update the code in staging, then push both live at the same moment, which is harder to coordinate than it sounds. Until it's done, you're wary of touching either side. You're essentially keeping two systems in lockstep, all by hand.
Git-based collapses all of that into a single commit. Content and code share one repository, so the model and the code that reads it move together and can't drift apart. Flip your content model on its head, restructure a whole content type, delete a redundant field: it's one changeset, reviewed and shipped like any other. Headless makes these changes expensive enough that you plan around them. Git-based makes them cheap enough that you can change your mind whenever you like.
Git-based content is natively AI-ready Direct link to this section
The advantage here is context. When your content lives in the same repository as the code that renders it, an AI tool can see everything at once: templates, components, data files, content. It understands how a blog post becomes a published page because the rendering logic is sitting right next to the post. It can traverse the whole codebase without hitting an API, without reconstructing relationships from paginated responses, without inferring structure from API schemas it's never seen before.
Try doing the same through a headless CMS. Every relationship between content types has to be inferred from responses. Every cross-reference is another network call. The LLM spends its tokens reconstructing context that, in a Git repo, would already be sitting in front of it.
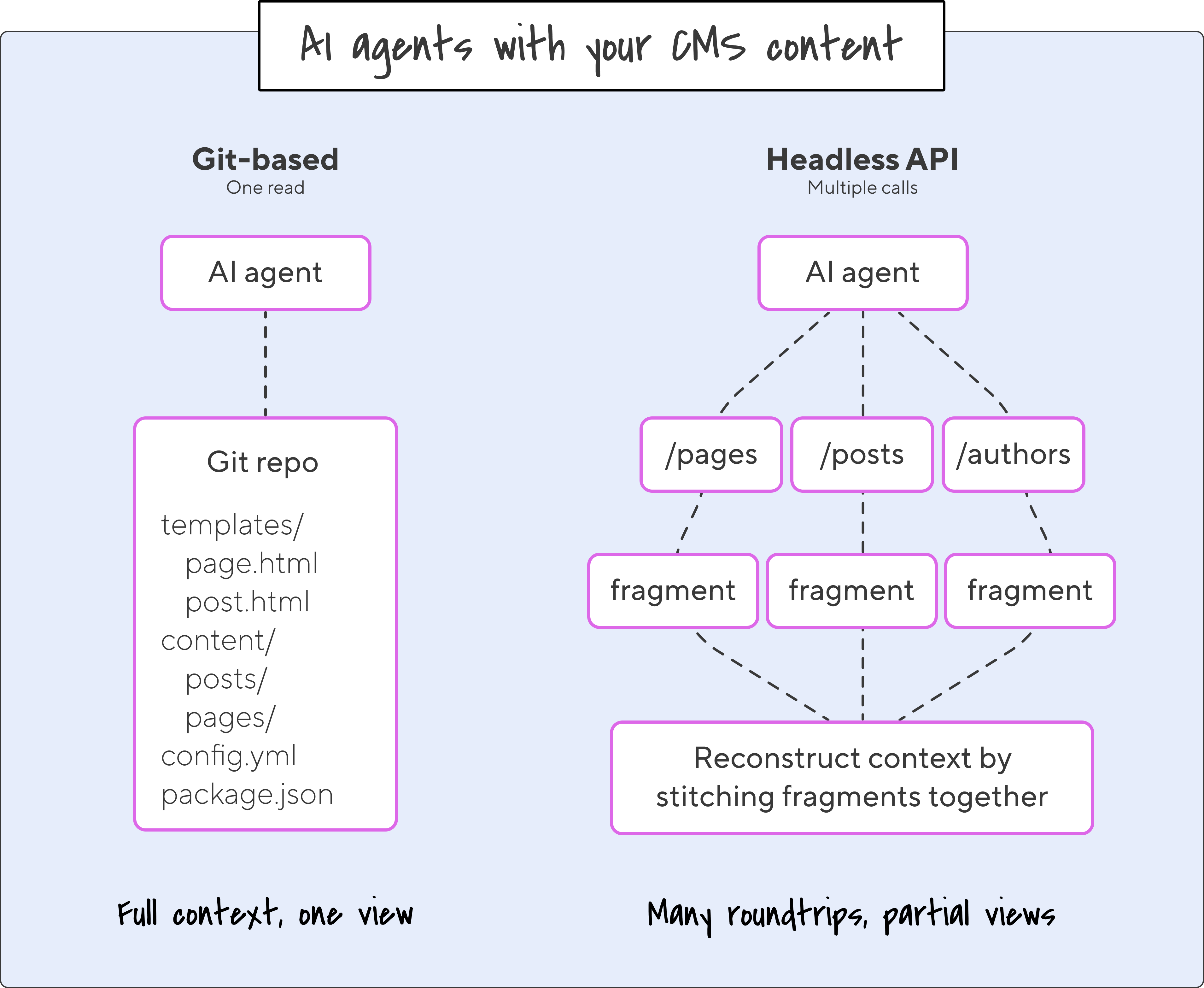
Because a Git CMS like CloudCannon works with your existing static site generator, your content is already in the markdown and structured data formats that AI tools handle best. There’s no proprietary content format to export from or transform. Your content is AI-ready the moment it’s saved.
And as AI agents become more and more standard in content workflows for tasks like generating drafts, translating pages, auditing for consistency, and answering questions from your knowledge base, a CMS that hands them the whole repo will pull ahead of one that makes them piece your content back together through an API, one call at a time.
Linear publishing pipelines break at AI speed Direct link to this section
There is one workflow problem that AI is making worse. Or at least, it’s making it more obvious. Most CMSs assume a single linear flow: draft, review, staging, publish. That worked when a content team produced two posts a week and refreshed a landing page once in a while. It doesn't hold up when things get busy, or when AI is in the mix.
With AI agents drafting copy, generating variants, auditing tone, and translating pages, your content team isn't limited to producing one thing at a time. You might have a landing page overhaul that's been running for three weeks, four blog posts in active drafting, a site-wide messaging refresh underway, and a translation project queued behind it.
A linear pipeline serializes that work. Whichever piece hits staging first blocks everything behind it. Reviewers context-switch between unrelated changes. A delay on a single blog post holds up a translation, a new component, even a crucial hotfix.
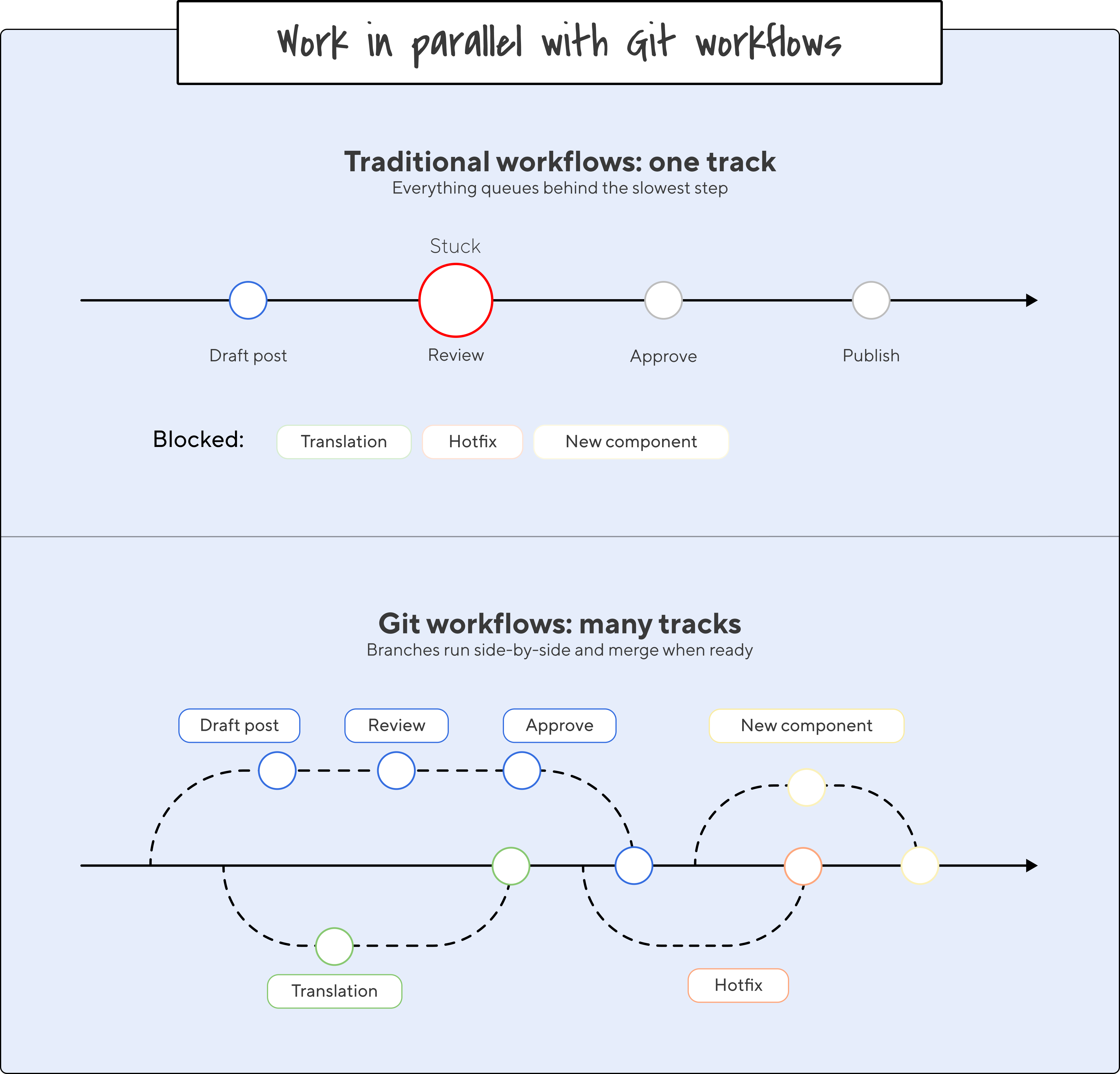
Git solved this for software decades ago with branches. Each workstream gets its own branch, its own preview environment, its own review cycle, and they merge when they're ready, independently of each other. CloudCannon brings that model to content editors. Editors, devs, and AI agents can work on parallel streams without stepping on each other’s toes. Reviewers can see exactly what's changing in each stream, separately.
That’s how we manage our website updates at CloudCannon.com: even with multiple branches in play across docs, landing pages, and new blog posts like this one, everything can be in motion all at once, and nothing gets blocked.
CMSs that store content in a single shared database don't have a clean answer to this publication workflow problem. You can try to build approval workflows on top, but the underlying model is still one canonical version of every page, edited by one person at a time.
The practical differences Direct link to this section
Monolithic | Headless | Git-based | |
|---|---|---|---|
Content portability | Locked in a tightly coupled database. Extraction requires migration tooling. | Stored in a vendor-specific database, accessible only via their API. | Plain files in a Git repo. You own them outright, and can move them wherever you want. |
AI accessibility | Inaccessible to LLMs without custom database integrations. | Requires API integrations, auth, pagination, and format transformation. | Readable by AI tools out of the box. Markdown and structured data are native LLM formats. |
Version control | Limited built-in revision history. | Vendor-managed versioning on their terms. | Full Git history (diffs, branches, rollbacks, and audit trails) for free. |
Editor experience | Familiar but coupled to the rendering layer. | Clean editing UI, decoupled from the frontend. | Visual editing with live previews and drag-and-drop components. Every change committed to Git behind the scenes. |
Vendor independence | Migrating away is a significant project. | Switching providers means rebuilding content integrations. | Your files work anywhere. We'd rather earn your loyalty than enforce it. |
Don’t just settle for headless Direct link to this section
“Headless” became shorthand for “modern CMS” somewhere around 2016, and the label seemed to stick. But I’d argue that decoupling the frontend was only half the job. If your content is still siloed in a proprietary database, you haven't actually freed it. And if your team is producing content faster than ever but your CMS only knows how to publish in a single order of operations, you walked straight into another bottleneck.
Content that's portable, version-controlled, branchable, and accessible to AI agents needs to live in Git. It needs to be in a repository you own, as files, in formats that humans, machines, and the rendering layer can all read without translation.
That's the approach CloudCannon was built on.
Launch your website today
Give your content team full autonomy on your developer-approved tech stack with CloudCannon.






